A forewarning, this post is me going out on a limb, to say the least. In fact, it’s a post/project requested from me by Brian Peterson, and it follows a new paper that he’s written on how to thoroughly replicate research papers. While I’ve replicated results from papers before (with FAA and EAA, for instance), this is a first for me in terms of what I’ll be doing here.
In essence, it is a thorough investigation into the paper “Leveraging Cloud Data to Mitigate User Experience from ‘Breaking Bad’”, and follows the process from the aforementioned paper. So, here we go.
*********************
Twitter Breakout Detection Package
Leveraging Cloud Data to Mitigate User Experience From ‘Breaking Bad’
Summary of Paper
Introduction: in a paper detailing the foundation of the breakout detection package (arXiv ID 1411.7955v1), James, Kejariwal, and Matteson demonstrate an algorithm that detects breakouts in twitter’s production-level cloud data. The paper begins by laying the mathematical foundation and motivation for energy statistics, the permutation test, and the E-divisive with medians algorithm, which create a fast way of detecting a shift in median between two nonparametric distributions that is robust to the presence of anomalies. Next, the paper demonstrates a trial run through some of twitter’s production cloud data, and compares the non-parametric E-divisive with medians to an algorithm called PELT. For the third topic, the paper discusses potential applications, one of which is quantitative trading/computational finance. Lastly, the paper states its conclusion, which is the addition of the E-divisive with medians algorithm to the existing literature of change point detection methodologies.
The quantitative and computational methodologies for the paper use a modified variant of energy statistics more resilient against anomalies through the use of robust statistics (viz. median). The idea of energy statistics is to compare the distances of means of two random variables contained within a larger time series. The hypothesis test to determine if this difference is statistically significant is called the permutation test, which permutes data from the two time series a finite number of times to make the process of comparing permuted time series computationally tractable. However, the presence of anomalies, such as in twitter’s production cloud data, would limit the effectiveness of using this process when using simple means. To that end, the paper proposes using the median, and due to the additional computational time resulting from the weaker distribution assumptions to extend the generality of the procedure, the paper devises the E-divisive with medians algorithms, one of which works off of distances between observations, and one works with the medians of the observations themselves (as far as I understand). To summarize, the E-divisive with medians algorithms exist as a way of creating a computationally tractable procedure for determining whether or not a new chunk of time series data is considerably different from the previous through the use of advanced distance statistics robust to anomalies such as those present in twitter’s cloud data.
To compare the performance of the E-divisive with medians algorithms, the paper compares the algorithms to an existing algorithm called PELT (which stands for Pruned Extract Linear Time) in various quantitative metrics, such as “Time To Detect”, meaning the exact moment of the breakout to when the algorithms report it (if at all), along with precision, recall, and the F-measure, defined as the product of precision and recall over their respective sum. Comparing PELT to the E-divisive with medians algorithm showed that the E-divisive algorithm outperformed the PELT algorithm in the majority of data sets. Even when anomalies were either smoothed by taking the rolling median of their neighbors, or by removing them altogether, the E-divisive algorithm still outperformed PELT. Of the variants of the EDM algorithm (EDM head, EDM tail, and EDM-exact), the EDM-tail variant (i.e. the one using the most recent observations) was also quickest to execute. However, due to fewer assumptions about the nature of the underlying generating distributions, the various E-divisive algorithms take longer to execute than the PELT algorithm, with its stronger assumptions, but worse general performance. To summarize, the EDM algorithms outperform PELT in the presence of anomalies, and generally speaking, the EDM-tail variant seems to work best when considering computational running time as well.
The next section dealt with the history and applications of change-point/breakout detection algorithms, in fields such as finance, medical applications, and signal processing. As finance is of a particular interest, the paper acknowledges the ARCH and various flavors of GARCH models, along with the work of James and Matteson in devising a trading strategy based on change-point detection. Applications in genomics to detect cancer exist as well. In any case, the paper cites many sources showing the extension and applications of change-point/breakout detection algorithms, of which finance is one area, especially through work done by Matteson. This will be covered further in the literature review.
To conclude, the paper proposes a new algorithm called the E-divisive with medians, complete with a new statistical permutation test using advanced distance statistics to determine whether or not a time series has had a change in its median. This method makes fewer assumptions about the nature of the underlying distribution than a competitive algorithm, and is robust in the face of anomalies, such as those found in twitter’s production cloud data. This algorithm outperforms a competing algorithm which possessed stronger assumptions about the underlying distribution, detecting a breakout sooner in a time series, even if it took longer to run. The applications of such work range from finance to medical devices, and further beyond. As change-point detection is a technique around which trading strategies can be constructed, it has particular relevance to trading applications.
Statement of Hypothesis
Breakouts can occur in data which does not conform to any known regular distribution, thus rendering techniques that assume a certain distribution less effective. Using the E-divisive with medians algorithm, the paper attempts to predict the presence of breakouts using time series with innovations from no regular distribution as inputs, and if effective, will outperform an existing algorithm that possesses stronger assumptions about distributions. To validate or refute a more general form of this hypothesis, which is the ability of the algorithm to detect breakouts in a timely fashion, this summary test it on the cumulative squared returns of the S&P 500, and compare the analysis created by the breakpoints to the analysis performed by Dr. Robert J. Frey of Keplerian Finance, a former managing director at Renaissance Technologies.
Literature Review
Motivation
A good portion of the practical/applied motivation of this paper stems from the explosion of growth in mobile internet applications, A/B testing, and other web-specific reasons to detect breakouts. For instance, longer loading time on a mobile web page necessarily results in lower revenues. To give another example, machines in the cloud regularly fail.
However, the more salient literature regarding the topic is the literature dealing with the foundations of the mathematical ideas behind the paper.
Key References
Paper 1:
David S. Matteson and Nicholas A. James. A nonparametric approach for multiple change point analysis of multivariate data. Journal of the American Statistical Association, 109(505):334–345, 2013.
Thesis of work: this paper is the original paper for the e-divisive and e-agglomerative algorithms, which are offline, nonparametric methods of detecting change points in time series. Unlike Paper 3, this paper lays out the mathematical assumptions, lemmas, and proofs for a formal and mathematical presentation of the algorithms. Also, it documents performance against the PELT algorithm, presented in Paper 6 and technically documented in Paper 5. This performance compares favorably. The source paper being replicated builds on the exact mathematics presented in this paper, and the subject of this report uses the ecp R package that is the actual implementation/replication of this work to form a comparison for its own innovations.
Paper 2:
M. L. Rizzo and G. J. Sz´ekely. DISCO analysis: A nonparametric extension of analysis of variance. The Annals of Applied Statistics, 4(2):1034–1055, 2010
Thesis of work: this paper generalizes the ANOVA using distance statistics. This technique aims to find differences among distributions outside their sample means. Through the use of distance statistics, the techniques aim to more generally answer queries about the nature of distributions (EG identical means, but different distributions as a result of different factors). Its applicability to the source paper is that it forms the basis of the ideas for the paper’s divergence measure, as detailed in its second section.
Paper 3:
Nicholas A. James and David S. Matteson. ecp: An R package for nonparametric multiple change point analysis of multivariate data. Technical report, Cornell University, 2013.
Thesis of work: the paper introduces the ecp package which contains the e-agglomerative and e-divisive algorithms for detecting change points in time series in the R statistical programming language (in use on at least one elite trading desk). The e-divisive method recursively partitions a time series and uses a permutation test to determine change points, but it is computationally intensive. The e-agglomerative algorithm allows for inputs from the user for initial time-series segmentation and is a computationally faster algorithm. Unlike most academic papers, this paper also includes examples of data and code in order to facilitate the use of these algorithms. Furthermore, the paper includes applications to real data, such as the companies found in the Dow Jones Industrial Index, further proving the effectiveness of these methods. This paper is important to the topic in question as the E-divisive algorithm created by James and Matteson form the base changepoint detection process for which the paper builds its own innovations for, and visually compares against; furthermore, the source paper restates many of the techniques found in this paper.
Paper 4:
Owen Vallis, Jordan Hochenbaum, and Arun Kejariwal. A novel technique for long-term anomaly detection in the cloud. In 6th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 14), June 2014.
Thesis of work: the paper proposes the use of piecewise median and median absolute deviation statistics to detect anomalies in time series. The technique builds upon the ESD (Extreme Studentized Deviate) technique and uses piecewise medians to approximate a long-term trend, before extracting seasonality effects from periods shorter than two weeks. The piecewise median method of anomaly detection has a greater F-measure of detecting anomalies than does the standard STL (seasonality trend loess decomposition) or quantile regression techniques. Furthermore, piecewise median executes more than three times faster. The relevance of this paper to the source paper is that it forms the idea of using robust statistics and building the techniques in the paper upon the median as opposed to the mean.
Paper 5:
Rebecca Killick and Kaylea Haynes. changepoint: An R package for changepoint analysis
Thesis of work: manual for the implementation of the PELT algorithm written by Rebecca Killick and Kaylea Haynes. This package is a competing change-point detection package, mainly focused around the Pruned Extraction Linear Time algorithm, although containing other worse algorithms, such as the segment neighborhoods algorithm. Essentially, it is a computational implementation of the work in Paper 2. Its application toward the source paper is that the paper at hand compares its own methodology against PELT, and often outperforms it.
Paper 6:
Rebecca Killick, Paul Fearnhead, and IA Eckley. Optimal detection of changepoints with a linear computational cost. Journal of the American Statistical Association, 107(500):1590–1598, 2012
Thesis of work: the paper proposes an algorithm (PELT) that scales linearly in running time with the size of the input time series to detect exact locations of change points. The paper aims to replace both an approximate binary partitioning algorithm, and an optimal segmentation algorithm that doesn’t involve a pruning mechanism to speed up the running time. The paper uses an MLE algorithm at the heart of its dynamic partitioning in order to locate change points. The relevance to the source paper is that through the use of the non-robust MLE procedure, this algorithm is vulnerable to poor performance due to the presence of anomalies/outliers in the data, and thus underperforms the new twitter change point detection methodology which employs robust statistics.
Paper 7:
Wassily Hoeffding. The strong law of large numbers for u-statistics. Institute of Statistics mimeo series, 302, 1961.
Thesis of work: this paper establishes a convergence of the mean of tuples of many random variables to the mean of said random variables, given enough such observations. This paper is a theoretical primer on establishing the above thesis. The mathematics involve use of measure theory and other highly advanced and theoretical manipulations. Its relevance to the source paper is in its use to establish a convergence of an estimated characteristic function.
Similar Work
In terms of financial applications, the papers covering direct applications of change points to financial time series are listed above. Particularly, David Matteson presented his ecp algorithms at R/Finance several years ago, and his work is already in use on at least one professional trading desk. Beyond this, the paper cites works on technical analysis and the classic ARCH and GARCH papers as similar work. However, as this change point algorithm is created to be a batch process, direct comparison with other trend-following (that is, breakout) methods would seem to be a case of apples and oranges, as indicators such as MACD, Donchian channels, and so on, are online methods (meaning they do not have access to the full data set like the e-divisive and the e-divisive with medians algorithms do). However, they are parameterized in terms of their lookback period, and are thus prone to error in terms of inaccurate parameterization resulting from a static lookback value.
In his book Cycle Analytics for Traders, Dr. John Ehlers details an algorithm for computing the dominant cycle of a security—that is, a way to dynamically parameterize the lookback parameter, and if this were to be successfully implemented in R, it may very well allow for improved breakout detection methods than the classic parameterized indicators popularized in the last century.
References With Implementation Hints
Reference 1: Breakout Detection In The Wild
This blog post is a reference contains the actual example included in the R package for the model, written by one of the authors of the source paper. As the data used in the source paper is proprietary twitter production data, and the model is already implemented in the package discussed in this blog post, this makes the package and the included data the go-to source for starting to work with the results presented in the source paper.
Reference 2: Twitter BreakoutDetection R package evaluation
This blog post is that of a blogger altering the default parameters in the model. His analysis of traffic to his blog contains valuable information as to greater flexibility in the use of the R package that is the implementation of the source paper.
Data
The data contained in the source paper comes from proprietary twitter cloud production data. Thus, it is not realistic to obtain a copy of that particular data set. However, one of the source paper’s co-authors, Arun Kejariwal, was so kind as to provide a tutorial, complete with code and sample data, for users to replicate at their convenience. It is this data that we will use for replication.
Building The Model
Stemming from the above, we are fortunate that the results of the source paper have already been implemented in twitter’s released R package, BreakoutDetection. This package has been written by Nicholas A. James, a PhD candidate at Cornell University studying under Dr. David S. Matteson. His page is located here.
In short, all that needs to be done on this end is to apply the model to the aforementioned data.
Validate the Results
To validate the results—that is, to obtain the same results as one of the source paper’s authors, we will execute the code on the data that he posted on his blog post (see Reference 1).
require(devtools)
install_github(repo="BreakoutDetection", username="twitter")
require(BreakoutDetection)
data(Scribe)
res = breakout(Scribe, min.size=24, method='multi', beta=.001, degree=1, plot=TRUE)
res$plot
This is the resulting image, identical from the blog post.

Validation of the Hypothesis
This validation was inspired by the following post:
The Relevance of History
The post was written by Dr. Robert J. Frey, professor of Applied Math and Statistics at Stony Brook University, the head of its Quantitative Finance program, and former managing director at Renaissance Technologies (yes, the Renaissance Technologies founded by Dr. Jim Simons). While the blog is inactive at the moment, I sincerely hope it will become more active again.
Essentially, it uses mathematica to detect changes in the slope of cumulative squared returns, and the final result is a map of spikes, mountains, and plains, the x-axis being time, and the y-axis the annualized standard deviation. Using the more formalized e-divisive and e-divisive with medians algorithms, this analysis will attempt to detect change points, and use the PerformanceAnalytics library to compute the annualized standard deviation from the data of the GSPC returns itself, and output a similarly-formatted plot.
Here’s the code:
require(quantmod)
require(PerformanceAnalytics)
getSymbols("^GSPC", from = "1984-12-25", to = "2013-05-31")
monthlyEp <- endpoints(GSPC, on = "months")
GSPCmoCl <- Cl(GSPC)[monthlyEp,]
GSPCmoRets <- Return.calculate(GSPCmoCl)
GSPCsqRets <- GSPCmoRets*GSPCmoRets
GSPCsqRets <- GSPCsqRets[-1,] #remove first NA as a result of return computation
GSPCcumSqRets <- cumsum(GSPCsqRets)
plot(GSPCcumSqRets)
This results in the following image:

So far, so good. Let’s now try to find the amount of changepoints that Dr. Frey’s graph alludes to.
t1 <- Sys.time()
ECPmonthRes <- e.divisive(X = GSPCsqRets, min.size = 2)
t2 <- Sys.time()
print(t2 - t1)
t1 <- Sys.time()
BDmonthRes <- breakout(Z = GSPCsqRets, min.size = 2, beta=0, degree=1)
t2 <- Sys.time()
print(t2 - t1)
ECPmonthRes$estimates
BDres$loc
With the following results:
> ECPmonthRes$estimates
[1] 1 285 293 342
> BDres$loc
[1] 47 87
In short, two changepoints for each. Far from the 20 or so regimes present in Dr. Frey’s analysis. So, not close to anything that was expected. My intuition tells me that the main reason for this is that these algorithms are data-hungry, and there is too little data for them to do much more than what they have done thus far. So let’s go the other way and use daily data.
dailySqRets <- Return.calculate(Cl(GSPC))*Return.calculate(Cl(GSPC))
dailySqRets <- dailySqRets["1985::"]
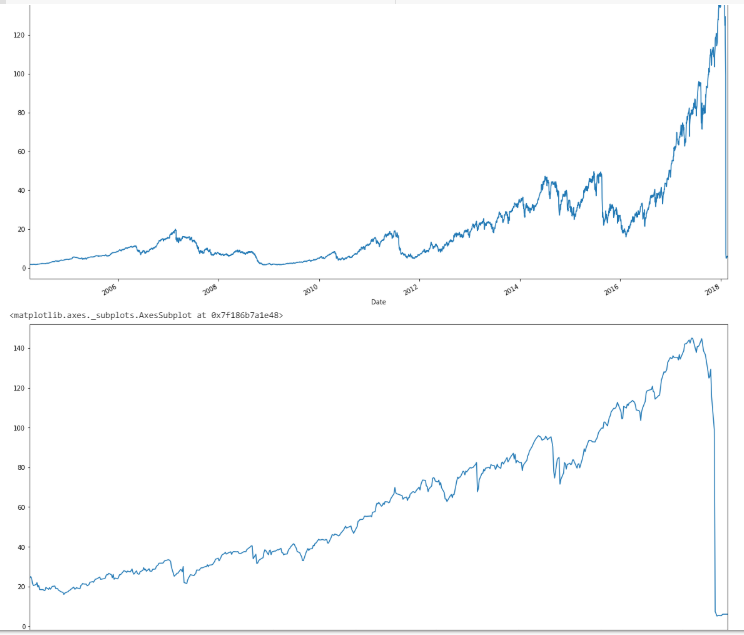
plot(cumsum(dailySqRets))
And here’s the new plot:

First, let’s try the e-divisive algorithm from the ecp package to find our changepoints, with a minimum size of 20 days between regimes. (Blog note: this is a process that takes an exceptionally long time. For me, it took more than 2 hours.)
t1 <- Sys.time()
ECPres <- e.divisive(X = dailySqRets, min.size=20)
t2 <- Sys.time()
print(t2 - t1)
Time difference of 2.214813 hours
With the following results:
index(dailySqRets)[ECPres$estimates]
[1] "1985-01-02" "1987-10-14" "1987-11-11" "1998-07-21" "2002-07-01" "2003-07-28" "2008-09-15" "2008-12-09"
[9] "2009-06-02" NA
The first and last are merely the endpoints of the data. So essentially, it encapsulates Black Monday and the crisis, among other things. Let’s look at how the algorithm split the volatility regimes. For this, we will use the xtsExtra package for its plotting functionality (thanks to Ross Bennett for the work he did in implementing it).
require(xtsExtra)
plot(cumsum(dailySqRets))
xtsExtra::addLines(index(dailySqRets)[ECPres$estimates[-c(1, length(ECPres$estimates))]], on = 1, col = "blue", lwd = 2)
With the resulting plot:

In this case, the e-divisive algorithm from the ecp package does a pretty great job segmenting the various volatility regimes, as can be thought of roughly as the slope of the cumulative squared returns. The algorithm’s ability to accurately cluster the Black Monday events, along with the financial crisis, shows its industrial-strength applicability. How does this look on the price graph?
plot(Cl(GSPC))
xtsExtra::addLines(index(dailySqRets)[ECPres$estimates[-c(1, length(ECPres$estimates))]], on = 1, col = "blue", lwd = 2)

In this case, Black Monday is clearly visible, along with the end of the Clinton bull run through the dot-com bust, the consolidation, the run-up to the crisis, the crisis itself, the consolidation, and the new bull market.
Note that the presence of a new volatility regime may not necessarily signify a market top or bottom, but the volatility regime detection seems to have worked very well in this case.
For comparison, let’s examine the e-divisive with medians algorithm.
t1 <- Sys.time()
BDres <- breakout(Z = dailySqRets, min.size = 20, beta=0, degree=1)
t2 <- Sys.time()
print(t2-t1)
BDres$loc
index(dailySqRets)[BDres$loc]
With the following result:
Time difference of 2.900167 secs
> BDres$loc
[1] 5978
> BDres$loc
[1] 5978
> index(dailySqRets)[BDres$loc]
[1] "2008-09-12"
So while the algorithm is a lot faster, its volatility regime detection, it only sees the crisis as the one major change point. Beyond that, to my understanding, the e-divisive with medians algorithm may be “too robust” (even without any penalization) against anomalies (after all, the median is robust to changes in 50% of the data). In short, I think that while it clearly has applications, such as twitter cloud production data, it doesn’t seem to obtain a result that’s in the ballpark of two other separate procedures.
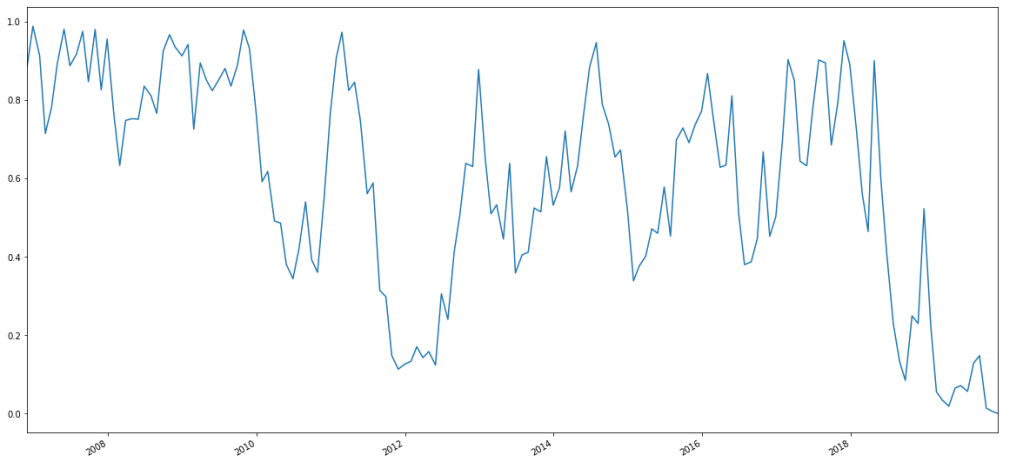
Lastly, let’s try and create a plot similar to Dr. Frey’s, with spikes, mountains, and plains.
require(PerformanceAnalytics)
GSPCrets <- Return.calculate(Cl(GSPC))
GSPCrets <- GSPCrets["1985::"]
GSPCrets$regime <- ECPres$cluster
GSPCrets$annVol <- NA
for(i in unique(ECPres$cluster)) {
regime <- GSPCrets[GSPCrets$regime==i,]
annVol <- StdDev.annualized(regime[,1])
GSPCrets$annVol[GSPCrets$regime==i,] <- annVol
}
plot(GSPCrets$annVol, ylim=c(0, max(GSPCrets$annVol)), main="GSPC volatility regimes, 1985 to 2013-05")
With the corresponding image, inspired by Dr. Robert Frey:

This concludes the research replication.
********************************
Whew. Done. While I gained some understanding of what change points are useful for, I won’t profess to be an expert on them (some of the math involved uses PhD-level mathematics such as characteristic functions that I never learned). However, it was definitely interesting pulling together several different ideas and uniting them under a rigorous process.
Special thanks for this blog post:
Brian Peterson, for the process paper and putting a formal structure to the research replication process (and requesting this post).
Robert J. Frey, for the “volatility landscape” idea that I could objectively point to as an objective benchmark to validate the hypothesis of the paper.
David S. Matteson, for the ecp package.
Nicholas A. James, for the work done in the BreakoutDetection package (and clarifying some of its functionality for me).
Arun Kejariwal, for the tutorial on using the BreakoutDetection package.
Thanks for reading.
NOTE: I am a freelance consultant in quantitative analysis on topics related to this blog. If you have contract or full time roles available for proprietary research that could benefit from my skills, please contact me through my LinkedIn here.






 As can be seen, a visibly higher variance in variances–in other words, a second moment on the second moment–meaning that to not use an order-sizing function that takes into account individual security risk therefore introduces unnecessary kurtosis and heavier tails into the risk/reward ratio, and due to this unnecessary excess risk, performance suffers measurably.Here are the individual security annualized standard deviations for the max dollar order sizing method:
As can be seen, a visibly higher variance in variances–in other words, a second moment on the second moment–meaning that to not use an order-sizing function that takes into account individual security risk therefore introduces unnecessary kurtosis and heavier tails into the risk/reward ratio, and due to this unnecessary excess risk, performance suffers measurably.Here are the individual security annualized standard deviations for the max dollar order sizing method: